Chapter 6: Evaluation & Monitoring – Keeping AI on Track
The Long Game
Building an AI system is one thing. Keeping it useful, accurate, and safe over time is another challenge entirely. This final layer is about quality control, continuous improvement, and making sure your AI assistant doesn't gradually transform into an unreliable loose cannon.
Think about any tool or system you use regularly. Without maintenance and monitoring, things decay. Software accumulates bugs, processes become outdated, and what worked yesterday might fail tomorrow. AI systems face these same challenges, plus some unique ones of their own.
Measuring What Matters
When you buy a car, you look at specifications like horsepower, fuel efficiency, and safety ratings. With AI, we need similar metrics, but they're less straightforward. How do you measure something as subjective as "helpfulness" or as complex as "reasoning ability"?
The AI industry has developed two main approaches. First, we have automated metrics that computers can calculate quickly. Perplexity measures how surprised the model is by text – lower surprise generally means better understanding. For tasks like translation or summarization, we can compare AI output to human-written references using scores like BLEU or ROUGE. These automated metrics are useful for quick checks, but they only tell part of the story.
The gold standard remains human evaluation. Real people judge whether responses are coherent, relevant, helpful, and appropriate. This takes more time and money than automated metrics, but captures nuances that algorithms miss. A response might score perfectly on automated metrics while being completely unhelpful to actual users.
The Benchmark Olympics
The AI world loves standardized tests. Every new model release comes with claims about beating previous records on various benchmarks. MMLU tests general knowledge across dozens of subjects. HellaSwag measures common sense reasoning. HumanEval checks coding ability.
These benchmarks serve a purpose – they let us compare models objectively and track progress over time. But they also have serious limitations. Some models seem suspiciously good at specific benchmarks, raising questions about whether they've been optimized to ace the test rather than develop genuine capabilities. It's like teaching to the test in schools – good scores don't always mean real understanding.
More importantly, benchmark performance often has little correlation with real-world usefulness. A model might score brilliantly on academic tests while failing at practical tasks your business actually needs. This is why smart organizations create their own evaluation sets based on actual use cases rather than relying solely on public benchmarks.
Safety: The Essential Layer
AI safety isn't optional anymore. These systems learn from vast amounts of internet text, which means they've absorbed humanity's biases, misconceptions, and worse. Without careful evaluation and mitigation, AI can perpetuate stereotypes, generate harmful content, or give dangerously wrong advice.
Bias detection has become a crucial part of AI evaluation. This means checking whether models treat different groups fairly, avoid stereotypes, and don't perpetuate historical prejudices. It's not just about avoiding obvious discrimination – subtle biases can be equally harmful and much harder to detect.
Red-teaming takes this further. Security experts and ethicists actively try to break AI systems, finding ways to make them generate harmful content or reveal sensitive information. It's like hiring ethical hackers to test your cybersecurity, except they're probing for logical vulnerabilities rather than technical ones. The goal is finding problems before malicious users do.
Guardrails provide the final safety layer. These are filters and controls that sit between the AI and users, blocking harmful requests and responses. Modern guardrails are sophisticated, catching not just obvious problems but subtle attempts to manipulate the system. The challenge is making them strict enough to ensure safety while not being so restrictive that they prevent legitimate uses.
Production Monitoring: Keeping Watch
Launching an AI system is just the beginning. The real work starts when actual users begin interacting with it at scale. Production monitoring tracks several critical aspects that determine whether your AI continues to deliver value.
Performance metrics tell you if the system is meeting user needs. Response times, error rates, and task completion rates provide quantitative measures. But qualitative feedback matters just as much – are users satisfied with the responses they're getting? User feedback mechanisms, from simple thumbs up/down to detailed surveys, help track satisfaction over time.
The world changes constantly, and AI systems can suffer from what we call drift. Data drift occurs when the types of queries users send start differing from what the model was trained on. Concept drift happens when the meaning or context of things changes – imagine an AI trained before COVID trying to understand "social distancing" or "zoom fatigue." Regular evaluation catches these issues before they seriously impact performance.
Cost monitoring might seem mundane but becomes critical at scale. AI API calls add up quickly, especially with sophisticated models and augmentation features. Tracking costs by user, feature, and use case helps identify optimization opportunities and prevents budget surprises.
Explainability: Opening the Black Box
One of AI's biggest challenges is explaining its decisions. When a model gives an answer, can it tell you why? This isn't just academic curiosity – in many industries, explainability is a legal requirement. Financial services need to explain credit decisions. Healthcare systems must justify diagnostic recommendations.
Modern techniques can provide various levels of explanation. Attention visualization shows which parts of the input most influenced the output. Feature attribution identifies key factors in decisions. Some models can even generate natural language explanations of their reasoning process.
The challenge is balancing explainability with capability. Often, the most powerful models are the least explainable, while simpler models that we can fully understand have limited capabilities. Finding the right balance depends on your specific use case and requirements.
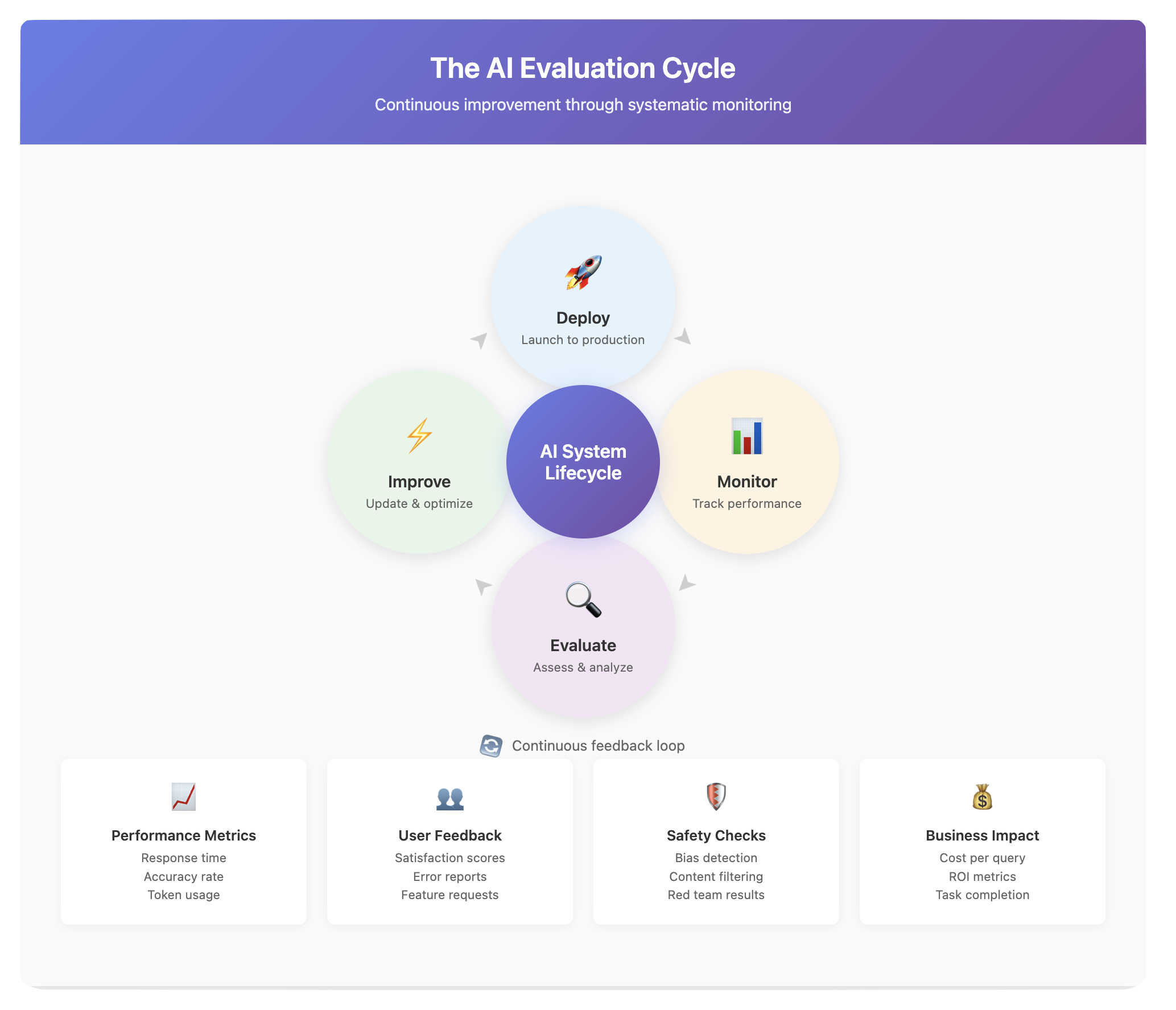
The Continuous Improvement Cycle
Evaluation and monitoring aren't one-time activities. They're part of a continuous cycle that keeps AI systems relevant and reliable. Regular evaluation identifies problems and opportunities. Monitoring catches issues as they emerge. Updates and improvements address what you've learned. Then the cycle repeats.
This iterative approach is especially important because both AI technology and user needs evolve rapidly. The model that perfectly served your needs six months ago might be outdated today. New models with better capabilities appear constantly. User expectations rise as they become more familiar with AI. Regulations and safety standards evolve.
Building Your Evaluation Framework
Every organization needs its own evaluation framework tailored to its specific needs. Start by identifying what really matters for your use cases. If you're using AI for customer service, response accuracy and tone might be critical. For internal research tools, comprehensiveness and source citation could matter more.
Create evaluation sets based on real examples from your domain. Include edge cases and difficult scenarios, not just typical queries. Regular testing against these sets helps you track performance over time and quickly identify when updates cause regressions.
Establish clear monitoring dashboards that track both technical metrics and business outcomes. Response times and error rates matter, but so do user satisfaction scores and task completion rates. Connect AI performance to actual business impact whenever possible.
Most importantly, build feedback loops that connect users, developers, and stakeholders. Users provide the most valuable insights about what's working and what isn't. Developers need this feedback to improve systems. Stakeholders need visibility into both successes and challenges.
The Reality Check
Perfect AI doesn't exist. Every system will make mistakes, show biases, and occasionally fail in unexpected ways. The goal isn't perfection but continuous improvement and risk mitigation. Good evaluation and monitoring help you catch problems early, understand their impact, and respond appropriately.
This is why Layer 6 might be the most important of all. Without proper evaluation and monitoring, you're flying blind. You won't know if your AI is helping or harming, improving or degrading, worth the investment or wasting resources. With good evaluation and monitoring, you can build AI systems that deliver real value while managing risks responsibly.
The six layers we've explored work together to create capable, reliable AI systems. Understanding each layer helps you make better decisions, whether you're choosing tools, building systems, or simply trying to use AI more effectively. The technology will keep evolving, but these fundamental concepts remain your guide to navigating the AI landscape successfully.
Visuals
License
© 2025 Uli Hitzel This book is released under the Creative Commons Attribution–NonCommercial 4.0 International license (CC BY-NC 4.0). You may copy, distribute, and adapt the material for any non-commercial purpose, provided you give appropriate credit, include a link to the license, and indicate if changes were made. For commercial uses, please contact the author.
Version 0.2, last updated November 2nd 2025