Chapter 1: Foundation – The Engine Room
How AI Actually Works
Let's start with a confession: when most people talk about "how AI works," they either dive into incomprehensible mathematics or hand-wave it away as "basically magic." We're going to do neither.
Understanding the foundation of LLMs is like understanding how a car engine works. You don't need to build one from scratch, but knowing the basics helps you drive better, troubleshoot problems, and avoid getting ripped off at the mechanic.
Breaking Language into Lego Blocks: Tokens
Here's the first surprise: AI doesn't actually read words the way you do. Instead, it breaks everything down into smaller pieces called tokens.
Take the sentence: "The dog barked loudly."
You see four words. The AI might see something like:
- "The"
- "dog"
- "bark"
- "ed"
- "loud"
- "ly"
Why does it do this? Because language is messy. Consider the word "unbelievable." Should AI learn this as one unit, or understand it as "un-believe-able"? By breaking words into common chunks, AI can handle new words it's never seen before. Encounter "unsingable" for the first time? No problem – it knows "un," it knows "sing," it knows "able."
This process is called tokenization, and it's the first step in how AI processes any text you give it. When AI generates a response, it's actually generating these tokens one by one, then assembling them back into readable text.
There's even a special token that acts like a period at the end of a sentence – the End-of-Sequence (EOS) token. When the AI generates this, it knows to stop talking. Without it, AI would ramble on forever like that relative at family dinners.
The Transformer: Where the Magic Happens
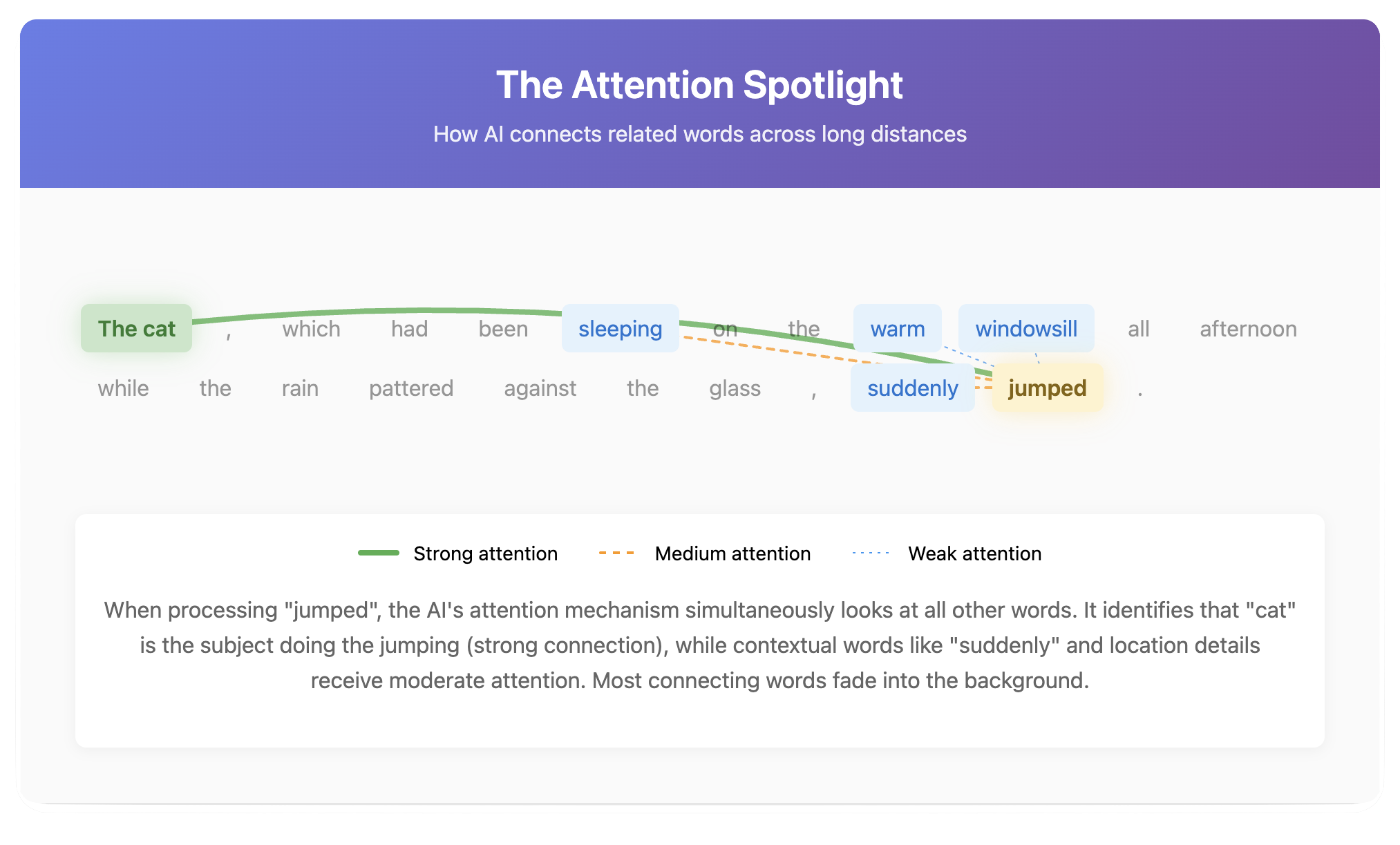
At the heart of every modern LLM is something called a Transformer. Despite the sci-fi name, it's not a robot in disguise. It's a design that solved a fundamental problem: understanding how words relate to each other across long distances in text.
Consider this sentence: "The cat, which had been sleeping on the warm windowsill all afternoon while the rain pattered against the glass, suddenly jumped."
What jumped? The cat. But there are 20 words between "cat" and "jumped." Earlier AI systems would lose track. Transformers solved this with a mechanism called attention.
Attention: The Cocktail Party Effect
Imagine you're at a busy cocktail party. Dozens of conversations are happening simultaneously, but you can focus on the one person talking to you while still being aware of the overall atmosphere. That's attention.
For each word in a sentence, the Transformer doesn't just look at neighboring words. It simultaneously considers every other word and decides which ones are most relevant. It's asking, "To understand 'jumped,' which other words in this sentence matter most?" The answer: "cat" matters a lot, "windowsill" matters some, "pattered" matters very little.
This happens through a clever system where each word generates three things:
- A Query: "What information am I looking for?"
- A Key: "What information do I have to offer?"
- A Value: "Here's my actual content"
Words with matching Queries and Keys pay more attention to each other. It's like each word is both broadcasting what it needs and advertising what it can provide.
Multi-Head Attention: Multiple Perspectives
Here's where it gets interesting. The Transformer doesn't just do this attention process once. It does it multiple times in parallel, each from a different "perspective."
Think of it like analyzing a movie scene. One person might focus on the dialogue, another on the cinematography, another on the music. Each perspective captures something different. Similarly, one "attention head" might focus on grammar, another on meaning, another on tone. Combining all these perspectives gives the AI a rich, nuanced understanding of text.
Position Matters
Since the Transformer looks at all words simultaneously, it needs another trick to remember word order. After all, "Dog bites man" and "Man bites dog" use the same words but mean very different things.
The solution: positional embeddings. Think of these as seat numbers at a theater. Each word gets tagged with its position, so even though all words are processed at once, the system knows which came first, second, third, and so on.
The Scale of Knowledge: Parameters
When you hear that an LLM has "7 billion parameters" or "175 billion parameters," what does that actually mean?
Parameters are essentially the AI's learned knowledge – millions or billions of numerical values that encode patterns, facts, and relationships the model discovered during training. Think of them as connections in a vast network, each holding a tiny piece of information.
More parameters generally means:
- More capacity to learn complex patterns
- Better performance on diverse tasks
- Higher costs to train and run
- More memory and processing power needed
But it's not just about size. A well-trained 7 billion parameter model can outperform a poorly trained 70 billion parameter model. Quality matters as much as quantity.
Making AI Practical: Quantization
Here's a problem: these billions of parameters take up enormous amounts of computer memory. A large model might need specialized hardware that costs tens of thousands of dollars to run.
Enter quantization – a technique that's like compressing a high-resolution photo. Instead of storing each parameter as a very precise number (like 3.14159265...), we round it to something simpler (like 3.14). The model becomes smaller and faster, with only a tiny loss in quality.
This is why you can now run decent AI models on your laptop or phone instead of needing a supercomputer.
How AI Generates Responses: The Two-Phase Process
When you send a prompt to an AI, two distinct phases happen:
Phase 1: Prefill (Reading)
The AI rapidly processes your entire prompt, building up its understanding of what you're asking. It's like speed-reading your question to grasp the full context before starting to answer.
Phase 2: Decode (Writing)
Now the AI generates its response, one token at a time. Each new token is predicted based on your original prompt plus everything it has already written. It's like writing a sentence where each new word must fit perfectly with everything that came before.
This is why AI responses appear word by word rather than all at once – it's literally figuring out what to say next as it goes.
The KV Cache: AI's Short-Term Memory
During the decode phase, the AI faces a challenge. To generate each new token, it needs to consider all previous tokens. Without optimization, it would have to re-read everything from scratch for each new word – incredibly inefficient.
The solution is the KV Cache (Key-Value Cache). It stores important calculations from previous tokens so they can be reused. It's like taking notes while reading a long document – instead of re-reading the whole thing to remember a detail, you check your notes.
This seemingly technical detail is why AI can maintain long conversations efficiently without slowing to a crawl.
Putting It All Together
These foundation elements – tokens, transformers, attention, parameters, quantization, and inference mechanics – work together to create what we experience as AI. Text comes in, gets broken into tokens, flows through layers of attention mechanisms guided by billions of parameters, and new tokens are generated one by one until a complete response emerges.
It's not magic. It's not human-like consciousness. It's a sophisticated pattern-matching and generation system that has learned from vast amounts of text to produce remarkably coherent and useful outputs.
Understanding this foundation helps explain both AI's impressive capabilities and its limitations. It can process and generate text with astounding skill because that's what it's designed to do. But it's not "thinking" in any human sense – it's performing incredibly complex calculations to predict the most likely next token based on patterns it has learned. When that prediction game drifts from the real world, we perceive the output as hallucination. In a poem or a story this creativity is welcome; in a facts-and-figures report it becomes a bug.
In the next chapter, we'll explore the landscape of different models built on this foundation and why you might choose one over another.
Visuals

License
© 2025 Uli Hitzel This book is released under the Creative Commons Attribution–NonCommercial 4.0 International license (CC BY-NC 4.0). You may copy, distribute, and adapt the material for any non-commercial purpose, provided you give appropriate credit, include a link to the license, and indicate if changes were made. For commercial uses, please contact the author.
Version 0.2, last updated November 2nd 2025